
이 책의 초판은 2012년 11월이고, 2020년에 2판이 나왔다. 2판은 ES6를 기준으로 작성되어있다. 코드 리팩터링의 기본 원칙에 대해 js로 풀어낸 것이므로, 객체지향 언어라면 대동소이하다.
사실 이 책에 나오는 내용 대부분은 학부 시절에 접할 수 있는 내용들이다. js로 작성되었다고해서 js 특성에 맞는 특별한 리팩터링 방법을 기대한다면 다른 책을 추천한다. 사실 ts가 나온 현 시점에서는 js라는 언어 자체가 리팩터링 대상이기 때문이다. 그냥 js가 대중적이니까 js판 리팩터링책을 만든 느낌이지, 다른 개발자들이 js쓰는 것을 보고 답답함을 느껴서 "야 너희들 js 리팩터링 그렇게 하는 거 아니야!"라는 느낌으로 책을 쓴 게 아니란 얘기다. 나는 사실 이 책의 작성 배경이 후자이길 바랐다.
만약 언어와는 무관하게 객체지향 언어에서 코드 리팩터링 방법, 좋은 코드의 기준 등이 궁금하다면, 이 책을 강력 추천한다. 갖가지 사례와 코드로 구성이 풍부하고, 다양한 관점을 갖고 설명을 해주기에 리팩터링에 대한 편향적 시각을 가지지 않을 수 있다.
1. TypeScript를 쓰자
물론 이 책의 핵심은 리팩터링에 대한 이론이다. 그저 js로 이론을 설명할 뿐... 동료들이 js판 리팩터링 책으로 스터디하자고 했을 때 거절한 적이 있는데, 그 이유는 js자체가 리팩터링 대상이라고 생각해왔기 때문이다. 리팩터링 대상인 언어로 책을 썼다는 이유로 '리팩터링 방법론에 대한 책이겠구나'라고 판단했다. 내가 js자체를 리팩터링 대상으로 보는 이유는 다음과 같다.
- js는 ts에 비해 "쓰기"에 좋은 언어이고, "읽기"와 "수정"에 좋은 언어는 아니다.
- ts는 js 프로젝트의 협업 능력과 가독성을 향상시키고자 등장했다.
- 리팩터링은 읽기, 수정하기 좋은 코드를 만드는 것이 목적이다.
개발자의 업무 시간 대부분은 뭔가를 읽는 시간이다
개발자는 뭔가를 읽고 생각하는 시간에 대부분의 시간을 사용하지, 작성하는 시간에 많은 시간을 소요하지 않는다. 만약 작성하는 것에 많은 시간을 소요하는 개발자라면, 개발을 잘못하고 있거나, 개발 업무가 아닐 가능성이 높다(퍼블리싱, 복붙, 데이터 입력, 운영, 문서 작성 등).
js는 작성하는 시간조차 아까운 코드인 경우나, 한번 작성하고 거의 읽지 않을 코드인 경우에만 유리하다. 그 코드를 읽는 사람도 개발자일 것이기 때문에 읽는 시간을 줄여주는 것이 작성하는 시간을 줄이는 것보다 이득이 큰 경우가 많다.
가독성은 데이터 모델만으로도 충분하다
이 책에서도 다음과 같이 얘기한다.
"데이터 테이블 없이 흐름도만 보여줘서는 나는 여전히 혼란스러울 것이다. 하지만 데이터 테이블만 보여준다면 흐름도는 웬만해선 필요조차 없을 것이다. 테이블만으로 명확하기 때문이다" - 프레드 브룩스Fred Brooks, 334p.
그렇다. 흐름이 중요한 게 아니라, 데이터 모델이 훨씬 중요하다. "흐름 작성"에 집중할 것이 아니라, "가독성"을 위한 상황이라면, 데이터 모델을 가시화해주는 TypeScript(이하 ts)를 사용하는 것이 더 큰 효과를 볼 가능성이 높다.
js에서는 함수 인자에 대한 데이터 타입을 docstring으로 어느 정도는 처리할 수 있다. 하지만 docstring은 일관성 유지가 어렵다. 그렇기 때문에 ts가 유리하다.
constructor 작성에서의 이점
js에서는 contructor 작성 시, 파라미터를 받아서 추가해주는 귀찮은 작업을 해야 한다.
class C {
constructor(p1, p2) {
this.p1 = p1
this.p2 = p2
}
}다음은 ts의 constructor작성법이다.
class C {
constructor(public p1, public p2) {}
}접근 제어자나 readonly등의 키워드로 클래스의 프로퍼티임을 즉시 명시해줄 수 있다. 코드가 짧아서 변경이 용이한 것이 핵심이다.
JS + Docstring vs TS
아래 코드를 보자. options의 데이터 타입을 IDE에서 제공 받으려면, 별도의 docstring을 추가해야 한다. 두 코드 모두 같은 동작을 하고, webstorm에서 동일한 타입 지원이 된다. 둘 다 충분히 깔끔하지만, foo2처럼 동일한 인풋을 다른 함수에서 받는 경우 더 많은 주석이 필요하다.
/**
*
* @param p1 {string}
* @param p2 {number}
*/
function foo({p1, p2}) {
return p1 + p2
}
/**
*
* @param options.p1 {string}
* @param options.p2 {number}
*/
function foo2(options) {
return foo(options)
}type FooOptions = { p1: string; p2: number; }
function foo({p1, p2}: FooOptions) {
return p1 + p2
}
function foo2(options: FooOptions) {
return foo(options)
}여전히 docstring + js가 가독성이 높고 유지보수 비용이 낮다고 생각하는가? 당신이 개발이 아닌 리팩터링을 시도하고 있다면, 글을 계속 읽어보자. 생각이 바뀔 것이다.
얼마나 수정하기 쉬운가
좋은 코드를 가늠하는 확실한 방법은 '얼마나 수정하기 쉬운가'다 - 76p.
데이터 타입 수정 시 TS의 이점
ts는 추가학습이 필요하지만 러닝 커브가 높은 편이 아니며, 큰 프로젝트에서 코드 일관성을 유지하는 데에 큰 도움이 된다. ts를 사용하는 것만으로도 데이터 모델 변경 시 필요한 테스트 코드를 꽤 줄일 수 있다. 플레인 오브젝트의 프로퍼티 이름이 변경된 경우, js는 테스트 코드를 돌려봐야만 확신할 수 있지만, ts는 타입하나 달아두면 일관성이 어긋난 부분에 대해 빌드에러를 내므로, DB 필드를 변경하는 게 아니라면 별도의 테스트 코드를 요구하지 않는다.
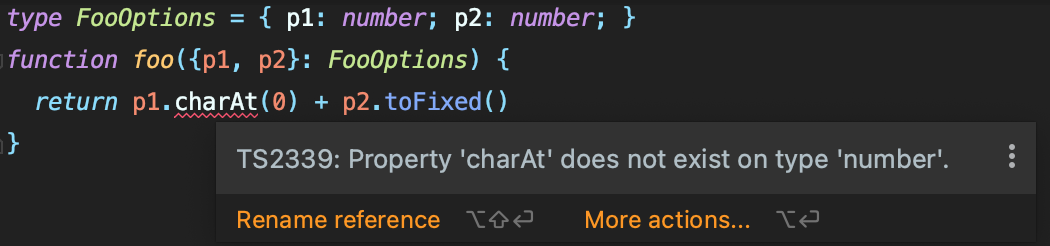
위 이미지처럼 FooOptions.p1을 number로 수정했을 때, FooOptions.p1을 string으로 간주하고 작성했던 코드들에서 에러가 나게 된다.
Function/Method Overloading
js에서 구현할 수 없는 ts의 또다른 이점이 있다. 바로 메소드/함수 오버로딩이다. 물론 ts의 메소드 오버로딩은 java의 오버로딩과는 달라서, 꼼수에 가깝고, ts의 오버로딩은 js에서도 기능 상으론 동일하게 구현할 수 있다. 차이점은 다른 개발자에게 노출되는 인터페이스에 있다. 다음 코드 캡쳐 화면을 보자.

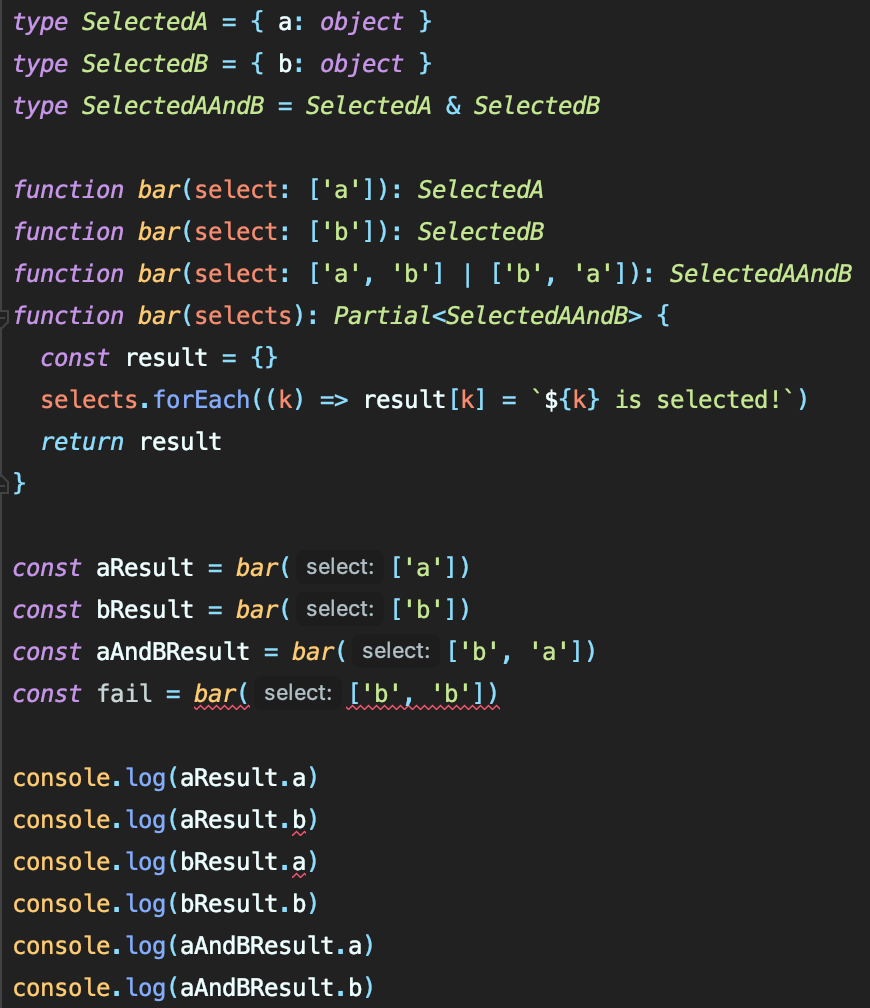
js 코드
/**
*
* @param selects {['a'], ['b'], ['a', 'b'], ['b', 'a']}
* @return {{a: Object, b: Object}}
*/
function bar(selects) {
const result = {}
selects.forEach((k) => result[k] = `${k} is selected!`)
return result
}
const aResult = bar(['a'])
const bResult = bar(['b'])
const aAndBResult = bar(['b', 'a'])
const fail = bar(['b', 'b'])
console.log(aResult.a)
console.log(aResult.b)
console.log(bResult.a)
console.log(bResult.b)
console.log(aAndBResult.a)
console.log(aAndBResult.b)ts 코드
type SelectedA = { a: object }
type SelectedB = { b: object }
type SelectedAAndB = SelectedA & SelectedB
function bar(select: ['a']): SelectedA
function bar(select: ['b']): SelectedB
function bar(select: ['a', 'b'] | ['b', 'a']): SelectedAAndB
function bar(selects): Partial<SelectedAAndB> {
const result = {}
selects.forEach((k) => result[k] = `${k} is selected!`)
return result
}
const aResult = bar(['a'])
const bResult = bar(['b'])
const aAndBResult = bar(['b', 'a'])
const fail = bar(['b', 'b'])
console.log(aResult.a)
console.log(aResult.b)
console.log(bResult.a)
console.log(bResult.b)
console.log(aAndBResult.a)
console.log(aAndBResult.b)js가 비교적 코드가 짧아졌다. 하지만 우리는 코드가 길어지더라도, 변경이 쉬운 코드 작성을 목표로 해야 한다. ts로 작성된 bar함수는 설계 의도대로 17, 20, 21줄에서 에러를 내는 것을 알 수 있다.
하지만 js는 인풋타입에 따라 아웃풋 타입이 달라지는 docstring은 작성할 수 없다(aResult.b와 bResult.a에 접근 가능). 뿐만 아니라, 유효하지 않은 인풋 타입에 대해 적절한 에러를 내지도 않는다(foo(['b', 'b'])호출 유효 처리).
ts의 코드가 더 길기 때문에, 개발일정이 급박하고 js가 훨씬 익숙하다면 js를 쓰는 것이 맞다. 하지만 개발이 아닌 리팩터링 업무를 진행 중이라면 ts가 큰 이점을 가져다 준다는 것에 동의하지 못할 사람은 없을 것이다.
2. 마틴 파울러가 그냥 지나친 것들
지금부터 얘기할 내용은 마틴 파울러가 언급하지 않은 내용들이다. 몰라서 언급하지 않은 것이라고 생각하지는 않지만, 부연설명이 필요해보이는 부분이 있어서 리팩터링 관점에서 추가적인 의견을 남긴다.
Set 자료형
리팩터링 책을 읽는 내내 Set자료형을 쓰는 것을 보지 못했다. 나는 성능 뿐 아니라, 가독성을 위해서라도 Set자료형을 쓰는 경우가 많다. Set이란 자료구조를 썼다는 것 자체만으로도 "'중복되지 않는' 원소집합이 필요하거나, 집합에서 존재 여부를 체크하려고 하는구나!"라고 알 수 있기 때문이다.
switch문을 사용할 수 있을 땐 항상 switch문을 사용하는 것과 동일하다. 세상 모든 switch문은 if문으로 변환 가능하지만, 역은 안 된다. Set와 Array도 마찬가지이다. Set로 구현한 기능은 Array로도 구현할 수 있지만, 역은 안 된다. 따라서 Set을 사용할 수 있을 땐 거의 대부분 Set을 사용한다. 데이터 크기가 커졌을 때 성능이 O(n)에서 O(1)로 개선되는 것은 덤이다.
prototype을 이용한 메소드 확장
아래 코드는 410쪽 마지막 코드이다.
["조커", "사루만"].isDisjointWith(people) 저런 집합 연산자를 추가해줬으면 좋겠다는 바람을 남기며 10장을 마쳤는데, 사실 아래처럼 개발자가 추가해줄 수 있긴 하다. 참고로 이 기능은 class 키워드가 등장하기 이전인 es5부터 지원했던 기능이다.
Array.prototype.isDisjointWith = function (arr) {
return arr.some((e) => this.includes(e))
}
console.log(['조커', '사루만'].isDisjointWith(['Terry', 'Jahong']))
console.log(['조커', '사루만'].isDisjointWith(['Jahong', '조커', 'Yungik']))물론 위 코드는 사이드 이펙트를 초래할 수 있다. 만약 라이브러리에서 저런 코드를 작성하고 있다면, 저렇게 쓰지말라고 강하게 피드백해야 한다. 그 이유는 다른 개발자가 prototype에 같은 이름, 다른 기능의 메소드를 추가할 가능성이 생기기 때문이다. 예를 들면 다음과 같다.
// 개발자A가 생각한 [].filterNumber
Array.prototype.filterNumber = function () {
return this.filter((v) => typeof v === 'number')
}
// 개발자B가 생각한 [].filterNumber
Array.prototype.filterNumber = function () {
return this.filter((v) => typeof v === 'number' && !isNaN(v))
}개발자A의 filterNumber는 NaN값을 포함하지만, 개발자B의 filterNumber는 NaN을 제외시킨다. 개발자B의 코드가 마지막에 적용되어서 개발자A의 코드를 덮는 경우에는 아마 큰 문제가 없을 것이다. 하지만 개발자A의 코드가 나중에 적용되는 경우, 개발자B는 버그 수정을 위해 사경을 헤맬 것이다.
굳이 굳이 prototype에 메소드를 추가하고 싶다면, 다음과 같이 쓰길 권장한다.
function foo() {
Array.prototype.filterNumber = function () {
return this.filter((v) => typeof v === 'number')
}
console.log([1, 2, 3, 'a', 'b', 'c'].filterNumber())
delete Array.prototype.filterNumber
}사용 전에 추가했다가, 사용 이후에 지워서 사이드이펙트를 없애는 방법이다. 사이드 이펙트 하나 잡겠다고 복잡하게 쓰기 보다는 그냥 dart처럼 extension 키워드를 추가하는 것이 바람직해보인다. ts에 extension키워드를 추가하고, js로 컴파일될 때 prototype에 메소드를 추가해주는 로직, 다 쓰고 나면 extension을 지우는 로직을 끼워넣어 사이드이펙트를 없애는 것이다.
마치며
앞서 말했듯, 나는 js라는 언어 자체를 리팩터링 대상으로 여기기 때문에, 이 책에서 js에 특화된 내용을 기대하지는 않았다. 코드 작성에 관한 이론적인 부분은 배울 것이 많을 수 있으나, js, ts 특징을 이용한 리팩터링 기법을 원한다면 이 책을 추천하지 않는다. 반대로 언어와는 상관없이 좋은 코드가 무엇인지에 대한 안목을 기르고 싶은 거라면 추천한다. 이상으로 Refactoring 2판에 대한 내 후기를 마친다.
'IT' 카테고리의 다른 글
| Node Engine 수정하기 (0) | 2022.12.10 |
|---|---|
| Android emulator에서 Push notification이 수신되지 않을 때 (0) | 2022.12.04 |
| 스벨트에서 readable만 노출하기(Svelte - writable to readable) (0) | 2022.10.10 |
| NestJS로 쉽게 개발하는 방법 (0) | 2021.03.27 |
| 기술 스택 전면 교체와 고려해야 할 사항 (8) | 2020.08.01 |